해당 학습 문서는 Hadoop과 Spark가 등장한 배경 및 주요 기능에 대한 대략적인 흐름을 보여주기 위해 작성되었습니다. 더 자세한 동작 원리 및 아키텍처는 다른 글들을 참고해주세요
빅데이터의 등장
2000년대 후반 스마트폰과 IoT기기들의 등장으로 데이터의 양과 이를 처리할 수 있는 시스템에 대한 수요가 기하급수적으로 증가했습니다. 이러한 데이터의 홍수(Exaflood)가 발생하자 기존의 인프라로 운영하기엔 네트워크 마비 및 스토리지 기술 문제가 발생했습니다. 2012년 4월 아마존 클라우드 컨퍼런스에서 data scientist 존 라우저(John Rauser) 이러한 빅데이터를 다음과 같이 정의했습니다.
“서버 한대로 처리할 수 없는 규모의 데이터”
그렇다면 이 방대한 데이터를 처리하기 위한 현실적인 대안은 무엇일까요?
Scale up의 한계
실제로 1980-90년대까지 IT 기업에서 데이터와 애플리케이션이 하나의 거대한 서버(메인프레임)에서 구동되는 방식이 표준이었습니다. 당시만해도 CPU의 성능과 메모리 용량이 2년마다 2배씩 증가하여, 데이터 처리 문제는 더 좋은 하드웨어로 해결할 수 있다는 인식이 지배적이었습니다. 하지만 다음과 같은 문제들에 봉착하면서 단순 중앙 집중식 아키텍처로는 한계가 찾아왔습니다.
- 비용의 한계 - 하드웨어의 성능을 높이기 위한 R&D 투자 비용과 생산 장비 비용이 함께 증가했습니다.
- 물리적 한계 - 서버 한 대에 꽂을 수 있는 CPU와 RAM의 물리적 한계가 찾아왔습니다
- 트래픽 처리의 한계 - 웹 서비스처럼 수많은 사용자가 동시에 접속하는 환경에서 적합하지 않았습니다.
이처럼 하나의 컴퓨터의 성능을 높이는 방식(Scale up, Vertical Scaling)의 한계로 인해 공학자들은 이를 대체할 방식을 강구하기 시작했습니다.
Scale out 분산처리 시스템

하나의 서버 컴퓨터로 처리하기 어렵다면 여러 대로 작업을 나누어 처리하면 되지 않을까? 이것이 Scale Out, Horizontal Scaling의 기본적인 아이디어었습니다. 이러한 방식으로 데이터를 분산하여 처리한 결과 다음과 같은 특징들을 발견했습니다.
- 비용 개선: 컴퓨터의 수는 증가했지만 그만큼 개별 컴퓨터의 하드웨어 요구 성능도 낮아졌습니다.
- 높은 확장성 및 부하 분산: 트래픽이 증가하면 서버를 추가(Add)하여 처리 능력을 무한히 늘리는 것이 가능했습니다.
- 고가용성 (High Availability): 여러 대의 서버로 구성되므로, 특정 서버에 장애가 발생해도 다른 서버가 요청을 처리하여 서비스 중단 없이 운영할 수 있습니다. 이는 Fault Tolerance와 밀접한 관련이 있습니다.
*Fault tolerance : 소수의 서버가 고장나도 시스템이 정상 작동하는 능력
Hadoop
Scale out 아이디어가 퍼지면서 이를 실제로 구현한 플랫폼들이 등장하기 시작했고, 그 중심에 있던 것이 Hadoop입니다.
Hadoop은 Doug Cutting이 구글이 발표한 두 편의 논문, The Google File System(2003)과 MapReduce: Simplified Data Processing on Large Clusters(2004)를 바탕으로 만든 오픈소스 프로젝트에서 출발했습니다. 처음에는 오픈소스 검색 엔진 Nutch의 하부 프로젝트로 시작했지만, 2006년 Apache에서 독립적인 프로젝트로 분리되며 본격적으로 발전하기 시작했습니다.
Apache Hadoop 공식 문서에서 자신들의 프로젝트를 다음과 같이 정의합니다.
간단한 프로그래밍 모델을 사용하여 컴퓨터 클러스터 전반에서 대규모 데이터 셋을 분산 처리할 수 있게 해주는 프레임워크
즉, Hadoop은 처음부터 한 대의 서버가 아닌 수백, 수천 대의 서버를 묶어 하나의 시스템처럼 동작하게 만드는 것을 목표로 설계되었습니다. 이러한 설계를 구현하기 위해 초기 Hadoop은 크게 두 축으로 구성됩니다.
- HDFS(Hadoop Distributed File System): 데이터를 여러 서버에 나누어 저장하는 분산 파일 시스템
- MapReduce: HDFS에 저장된 데이터를 분산 처리하는 실행 엔진
간단히 정리하자면, HDFS가 창고라면 MapReduce는 그 창고에서 물건을 꺼내 처리하는 작업 방식으로 이해할 수 있습니다.
HDFS

HDFS는 대용량 파일을 일정한 크기의 블록으로 나누어 저장합니다
- 블록의 크기는 128MB를 default값으로 가지며 data block은 data node의 filesystem에 저장됩니다.
- 이러한 데이터 블록을 저장하고 관리하는 물리적 서버를 data node라고 합니다.
- data node는 worker/slave node 불립니다.
각 노드 마다 블록을 복제하는 방식을 Replication이라고 합니다
- 기본 복제 계수는 3으로 각 블록을 3개의 data node에 저장하는 방식입니다.
- 이를 통해 Fault tolerance를 보장할 수 있습니다.
name node는 HDFS에서 파일 시스템의 디렉터리 구조와 위치 정보를 담은 메타데이터를 총괄 관리하는 노드입니다
- 파일 이름, 디렉터리 구조, 파일 크기, 권한, 블록 목록 등의 정보를 메모리(RAM)에서 관리합니다.
- datanode가 보내는 Heartbeat를 받아 어떤 노드가 살아있는지 모니터링합니다.
- 특정 파일이 어떤 데이터노드의 블록들에 나누어 저장되어 있는지 매핑 정보를 기록합니다.
- datanode가 고장나면 다른 노드에 데이터 복제본을 만들도록 지시하여 데이터 유실을 막습니다.
- name node가 고장나면 HDFS 클러스터 전체가 즉시 마비되어 데이터에 접근할 수 없습니다. 이를 해결하기 위해 Hadoop 2.x버전부터는 name node를 두 대 이상 두는 고갸용성(HA) 기능을 제공합니다.
MapReduce
HDFS에 데이터를 분산 저장했다면, 이제 그 데이터를 어떻게 처리할지가 문제입니다. 기존 방식대로라면 흩어진 데이터를 한 곳으로 모아 처리해야 하는데, 데이터가 수 TB에 달한다면 이 자체가 불가능합니다. MapReduce는 발상을 뒤집어 이를 해결했습니다.
데이터를 프로그램으로 가져오지 말고, 프로그램을 데이터가 있는 곳으로 보내자
각 서버가 자신이 가진 데이터를 직접 처리하게 하는 것입니다. 이 실행 방식은 크게 세 단계로 이루어집니다.
Map → Shuffle → Reduce

Map은 데이터를 쪼개고 분류하는 작업이고 Reduce는 이를 모아서 최종결과를 냅니다
- Map → Reduce로 가는 과정을 Shuffling이라고 부르며 네트워크를 통한 데이터 이동이 생깁니다.
Map Reduce 프로그램의 dataset은 Key, Value의 집합이며 immutable 합니다
- 안전한 병렬 처리 (동시성 제어 불필요): 여러 노드에서 동시에 데이터를 읽고 처리할 때, 데이터가 변경되지 않는다면 락(Lock)을 걸거나 동시성 문제를 해결하기 위한 복잡한 로직이 필요 없어 성능이 극대화됩니다.
- 결정론적 결과 보장 및 장애 복구(Fault Tolerance): 처리 도중 특정 노드가 다운되더라도, 원본 데이터가 변경되지 않았으므로 해당 작업만 다른 노드에서 똑같이 재실행(Re-run)하면 정확히 같은 결과를 얻을 수 있습니다.
- 원자성(Atomicity)과 데이터 일관성: 여러 맵(Map) 및 리듀스(Reduce) 작업이 실행되는 동안 데이터가 중간에 수정되지 않으므로, 전체 시스템의 데이터 일관성을 유지할 수 있습니다.
데이터 조작은 map과 reduce 오퍼레이션만으로 가능합니다
- 두 오퍼레이션은 항상 하나의 쌍으로 연속 실행됩니다.
- 두 오퍼레이션의 코드는 개발자가 채워야 합니다.
Map
Mapping 함수의 수식표현은 다음과 같습니다.
- 입력 데이터의 형태를 분석하기 좋은 형태(key-value 쌍)로 가공하고 바꾸는 과정을 표현한 수식입니다.
- 사용자가 분석할 HDFS 파일을 지정하면, 시스템이 이를 자동으로 (k, v) 쌍으로 가공하여 Map 함수의 입력으로 넘겨줍니다.
- 입력과 동일한 (k, v) 쌍을 그대로 출력해도 되고(조건 필터링) 출력이 없어도 된다(Output = 0)
Reduce
\(Reduce:(k_{2},list(v_{2}))\rightarrow list(k_{3},v_{3})\)
- Map 단계와 Shuffling 과정을 거쳐 동일한 Key별로 묶인 데이터 그룹을 최종 집계(합산, 평균 등)하는 과정을 표현한 수식입니다.
- 시스템이 Shuffling을 통해 같은 Key를 가진 Value들을 리스트(list(v2)) 형태로 묶어주면, 이를 입력받은 Reduce 함수가 본격적인 연산을 시작합니다.
- 입력 데이터의 양을 압축하여 하나의 값으로 요약하는 것이 일반적이지만, 분석 목적에 따라 출력 결과가 여러 개이거나 없을 수도 있습니다.
- 최종 계산된 데이터는 다시 새로운 주성분인(k3, v3) 쌍으로 출력되며, 이 결과물은 지정된 HDFS 파일에 최종 저장되면서 MapReduce 전체 프로세스가 마무리 됩니다.
Word Count 예제

MapReduce의 동작을 나타낼 때 가장 흔히 사용하는 예시입니다. 이를 단계별로 설명하면 다음과 같습니다.
1. [Input Split]
- 대용량 원본 텍스트 파일을 HDFS에서 적당한 크기로 Split하여 읽어옵니다.
- 위의 이미지에서 총 3개의 블록으로 나누어 입력데이터를 가져왔습니다.
2. [Map]
- 입력된 텍스트 데이터를 한 줄씩 읽으면서 단어 단위로 분리하고 , (Key, Value) 형태의 쌍으로 변환합니다.
- 이미지에서 (Key, Value)쌍을 (단어, 등장 횟수)로 설정한 것을 볼 수 있습니다.
- 모든 단어의 초기 개수를 1로 매핑합니다
3. [Shufffle]
- 여러 Map 작업자가 생성한 결과물 중에서 동일한 Key를 가진 데이터들끼리 모아서 정렬하고 그룹화하는 과정입니다. 네트워크를 통해 데이터가 이동하므로 MapReduce에서 가장 많은 비용을 소비하는 단계입니다.
4. [Reduce]
- 셔플 단계를 거쳐 같은 Key끼리 묶인 리스트를 받아, 사용자가 정의한 로직(여기서는 합산)에 따라 데이터를 압축합니다.
5. [Output]
- Reduce 연산이 완료된 최종 결과를 파일 시스템에 저장합니다.
Shuffle and Sort
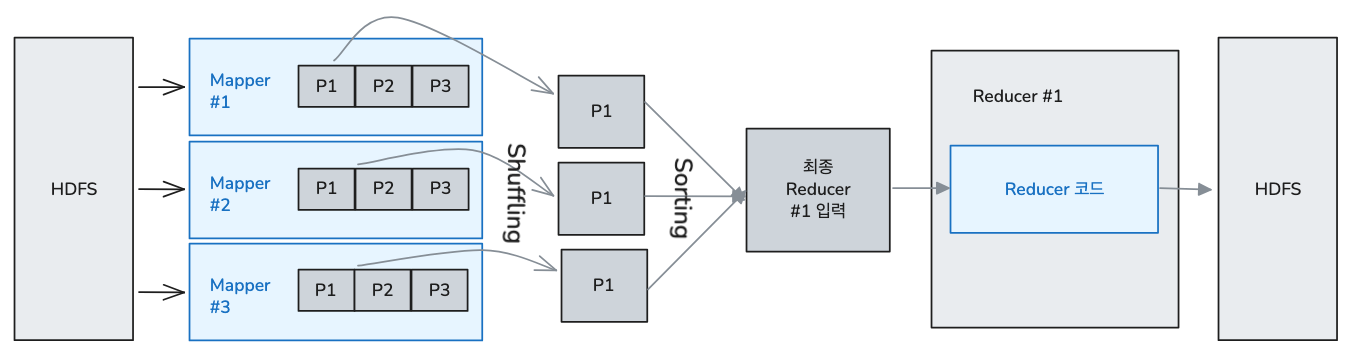
위 이미지를 기준으로 아래와 같이 설명했습니다.
Mapper 작업 및 파티셔닝
- HDFS에서 읽어온 데이터를 처리하기 위해 3개의 독립된 Mapper(작업자)가 동시에 작동하고 있습니다.
- 각 Mapper는 결과를 낼 때 그냥 내보내지 않고, 뒤에 올 Reducer의 개수에 맞춰 데이터를 쪼개어 저장합니다. 이 과정을 Partitioning이라고 합니다.
- 각 Mapper 내부에 P1, P2, P3라는 3개의 Partition이 나뉘어 있는 것을 볼 수 있습니다.
Shuffle
- 여러 노드에 흩어져 있는 Mapper들의 결과물 중에서 동일한 Partition 번호(P1)를 가진 데이터만 골라 네트워크를 통해 한 곳으로 모으는 과정입니다.
- 전송되는 데이터의 크기가 크면 네트워크 병목을 초래하고 시간이 오래 걸립니다.
Sorting
- Shuffling을 통해 네트워크에 수집된 P1 데이터들은 아직 순서 없이 뒤섞여 있습니다. 이를 Reducer가 연산하기 좋게 Key 순서대로 깔끔하게 정렬합니다.
참고로 MapReduce의 과정은 하나의 코드로 원하는 최종결과를 얻기 어렵습니다. MapReduce를 쇠사슬처럼 엮어서 실행하는 반복적인 Chaining과정이 필요합니다. 이는 복잡한 대용량 데이터의 구조를 비교적 단순한 하나의 MapReduce 함수로 처리하는 것이 불가능하기 때문입니다. 그외에도 Sorting의 한계, 다중 Join의 복잡성, 알고리즘 자체의 반복성의 이유가 있습니다.
Hadoop 1.0의 분산 처리 계층

이러한 MapReduce를 통한 분산처리과정이 초기 hadoop 엔진에서 관리하는 방법을 자세히 알아보겠습니다. 분산처리 시스템은 기본적으로 여러 task를 수행하는 서버 여러 대와 이들을 관리하는 중앙 시스템의 구조를 갖고 있습니다. Hadoop에서는 이들을 JobTracker(Master)와 TaskTracker(slave)라고 부릅니다.
JobTracker
Client가 던진 MapReduce 작업을 받아 전체적인 마스터 플랜을 짭니다. 코드를 몇개로 쪼개어 어느 TaskTracker에 보낼지 결정하고 감시합니다.
Task Tracker
각 서버에서 상주하며, Job Tracker가 보낸 명령에 따라 자기 컴퓨터의 CPU와 메모리를 켜서 실제로 Map이나 Reduce 함수를 실행합니다.
Map-Shuffle-Reduce의 단계별 작동 메커니즘

1. Map 단계 (데이터 변환)
- JobTracker: 입력할 데이터가 HDFS의 어느 DataNode들에 흩어져 있는지 파악합니다. 데이터가 있는 바로 그 서버의 TaskTracker에게 저장된 데이터로 Map task를 실행하라고 명령합니다. (Data Locality 보장)
- TaskTracker: 명령을 받으면 로컬 디스크의 데이터를 읽어와 개별 Map Task를 실행합니다. 결과를 자기 컴퓨터의 로컬 디스크(임시 저장소)에 저장하고, 완료되었다고 JobTracker에게 보고합니다.
2. Shuffle 단계 (데이터 이동 및 정렬)
- JobTracker: 모든 TaskTracker의 Map 작업이 끝났는지 모니터링합니다. Map이 끝나면 각 TaskTracker들에게 서로 데이터를 주고 받아 Key별로 모으라고 지시합니다.
- TaskTracker: 각 TaskTracker는 자신이 가진 Map 결과물을 그룹핑할 Key를 기준으로 분류합니다. 이후, 네트워크를 통해 다른 TaskTrakcer들과 데이터를 교환(HTTP 통신)하여 같은 키를 가진 데이터들을 한 곳으로 모으고 정렬합니다.
3. Reduce 단계 (최종 집계)
- JobTracker: Shuffle을 통해 데이터 정렬이 끝나면, 최종 집계를 담당할 Reduce Task를 특정 TaskTracker들에게 할당합니다.
- TaskTracker: 할당 받은 TaskTracker는 정렬된 데이터 그룹을 합산/집계하는 Reduced Task를 실행합니다. 최종 결과물이 나오면 이를 로컬이 아닌 HDFS에 안전하게 저장하고 JobTracker에게 작업 끝을 알립니다.
Hadoop의 한계
1. 과도한 디스크 I/O 연산 비용
Map 결과 → 디스크 저장 → Shuffle → 디스크 저장 → Reduce → 디스크 저장
- 각 단계의 중간 결과를 매번 디스크에 기록합니다. 한 번의 배치 작업이라면 문제가 없지만, 머신러닝처럼 같은 데이터를 반복해서 읽고 계산해야 하는 작업에서는 매 반복마다 디스크 읽기/쓰기가 발생해 속도가 크게 떨어졌습니다.
- 기본적으로 배치 처리 모델이기 때문에 데이터를 실시간으로 처리해야 하는 상황에는 적합하지 않았습니다.
2. MapReduce의 Data Skew

분산 처리 시스템의 전체 성능은 가장 늦게 끝나는 Task의 속도에 의해 결정됩니다
- Mapper의 불균형: 기본적으로 파일 블록 단위로 균등하게 할당 받지만, 특정 블록에 복잡한 데이터가 몰려있을 경우 Mapper간 처리 속도 차이가 발생합니다.
- Reducer의 불균형 (Group By, Join의 한계): Shuffling 단계에서 동일한 Key를 가진 데이터가 한 곳으로 모입니다. 만약 특정 Key(예: 대형 브랜드, 유명인 ID 등)의 데이터가 압도적으로 많다면, 특정 Reducer 하나에만 수십 배의 데이터가 몰리는 Data Skew현상이 발생합니다.
3. JobTracker 구조 문제
자원과 연산의 결합
Hadoop 1.0에서 JobTracker 하나가 클러스터 전체의 자원 관리와 작업 실행 및 모니터링을 모두 처리했습니다.
확장성의 한계(병목현상)
데이터가 커지고 작업(Job)이 늘어나면 JobTracker 하나에 과부하가 걸려 클러스터 규모를 늘리는 데 한계가 있었습니다.
YARN (Yet Another Resource Negotiator)
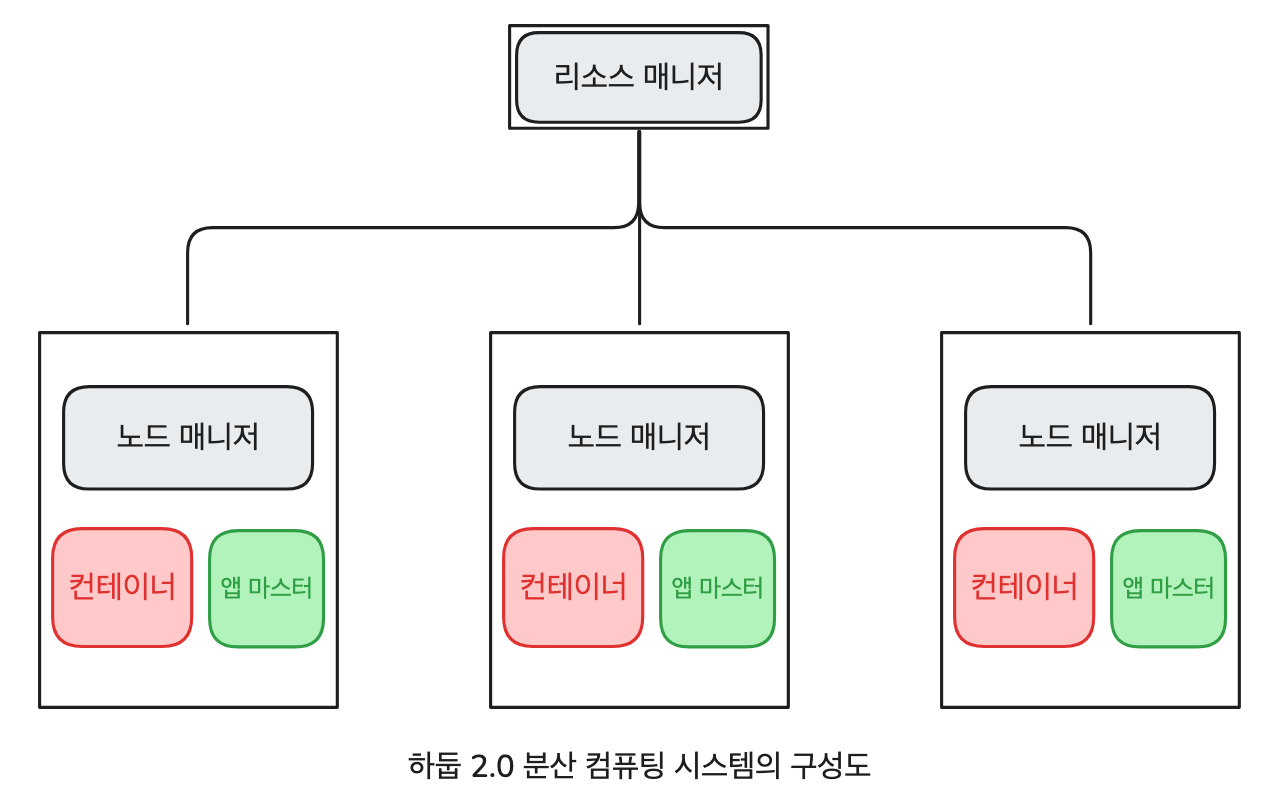
Hadoop 1.x 버전이 가진 JobTracker의 구조적인 문제를 해결하고자 Hadoop 2.x부터 YARN 시스템을 도입했습니다. YARN의 주요 역할은 JobTracker가 하던 일 중 클러스터 리소스 관리와 작업의 실행 제어입니다. 이러한 분리를 통해 시스템이 보다 안정되었으며 MapReduce뿐만 아니라 Spark와 같은 데이터 처리 프레임워크도 실행할 수 있게 되었습니다.
ResourceManager
- 클러스터 전체 리소스 관리자
- Job Scheduler, ApplicationManager의 요청을 받는 대상
NodeManager
- 각 worker node의 컨테이너 실행/감시자
ApplicationMaster
- 특정 application 하나의 실행 관리자
- container 안에서 실행되는 프로세스이며, 이때 container를 AM container라고 부름
Container
- CPU/메모리 같은 리소스를 할당받은 실행 공간
여기서 application은 사용자가 제출한 하나의 분산 작업 단위라고 생각하면 됩니다. MapReduce Job 하나일 수도 있고, Spark application 하나일 수도 있습니다. 따라서 YARN에서 application은 단순한 코드 파일이 아니라, AM + 여러 container/task + 실행 상태를 포함하는 하나의 실행 단위입니다.
YARN의 동작

- 클라이언트가 RM에게 application 실행 요청을 제출한다.
- RM이 어떤 NM에게 첫 container를 할당해서 AM을 띄운다.
- AM이 RM에게 application을 실행하기 위해 필요한 container를 요청한다.
- RM이 container들을 할당하면, AM이 NM들에게 task 실행을 지시한다.
- task/container 상태는 NM과 AM을 통해 추적되고, AM은 application 전체 진행 상황을 관리한다.
'Spark' 카테고리의 다른 글
| Spark 실행 모델 - RDD부터 Task까지 (0) | 2026.05.14 |
|---|
